"If we press the button, would the robot survive the stop?"
This is the core safe-stoppability question. The answer depends on the current state, the fixed fallback controller, and whether the robot can safely reach a minimum-risk condition.
Project Website
Video of the learned safe-stop behavior, the monitor, and the loco-manipulation task used for the hardware and simulation studies.

Overview
Instead of treating safety as an immediate shutdown, the paper studies whether a humanoid remains inside a safe-stoppable envelope: states from which a predefined fallback controller can still reach a safe terminal posture without falling or colliding.
"If we press the button, would the robot survive the stop?"
This is the core safe-stoppability question. The answer depends on the current state, the fixed fallback controller, and whether the robot can safely reach a minimum-risk condition.
Humanoid emergency stops are fundamentally different from power cutoffs used on fixed-base machines. A stop must preserve balance, manage contact, and steer the system toward a stable minimum-risk condition.
PRISM reframes this as a policy-dependent reach-avoid problem. Rather than certifying the entire state space, it focuses on the nominal task states the robot actually visits, then learns whether a safe stop remains feasible from each of those states.

The fallback controller is designed to preserve balance and drive the robot to a benign terminal posture instead of abruptly removing actuation.
The monitor is trained on the states encountered during task execution, which keeps the problem practical for high-dimensional humanoid systems.
The learned confidence can trigger the fallback policy before the robot crosses into states from which a safe stop is no longer possible.
Method
The paper introduces PRISM, a simulation-driven framework for learning a neural safe-stoppability monitor under a fixed fallback controller. The key idea is to spend the simulation budget where failures are rare but most informative: near the safe versus unsafe boundary.
Record the state distribution induced by the task policy instead of attempting to cover the full humanoid state space.
Reset the simulator to sampled states, execute the fallback controller, and label each state as safe or unsafe depending on whether the stop succeeds.
Learn a state-conditioned predictor that estimates the probability that the safe stop will reach the terminal posture without intermediate failure.
Use importance sampling to focus new labels on uncertain or error-prone regions, improving unsafe-state recall under a fixed rollout budget.
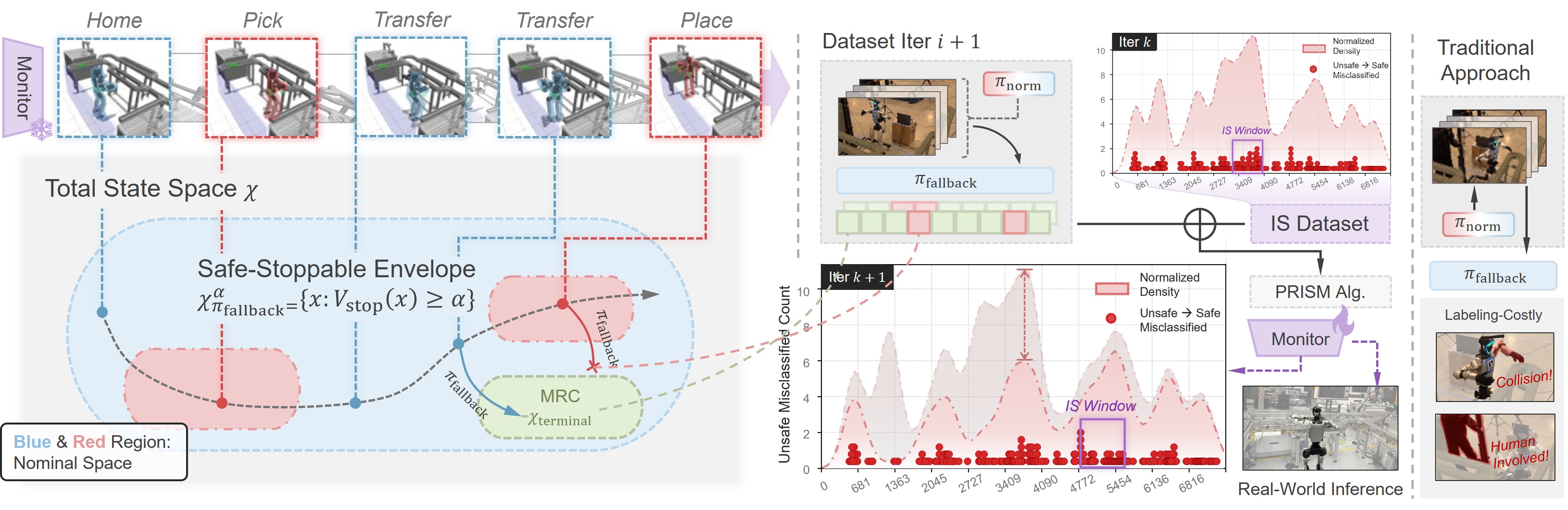
Safe-Stoppability Monitor Learning
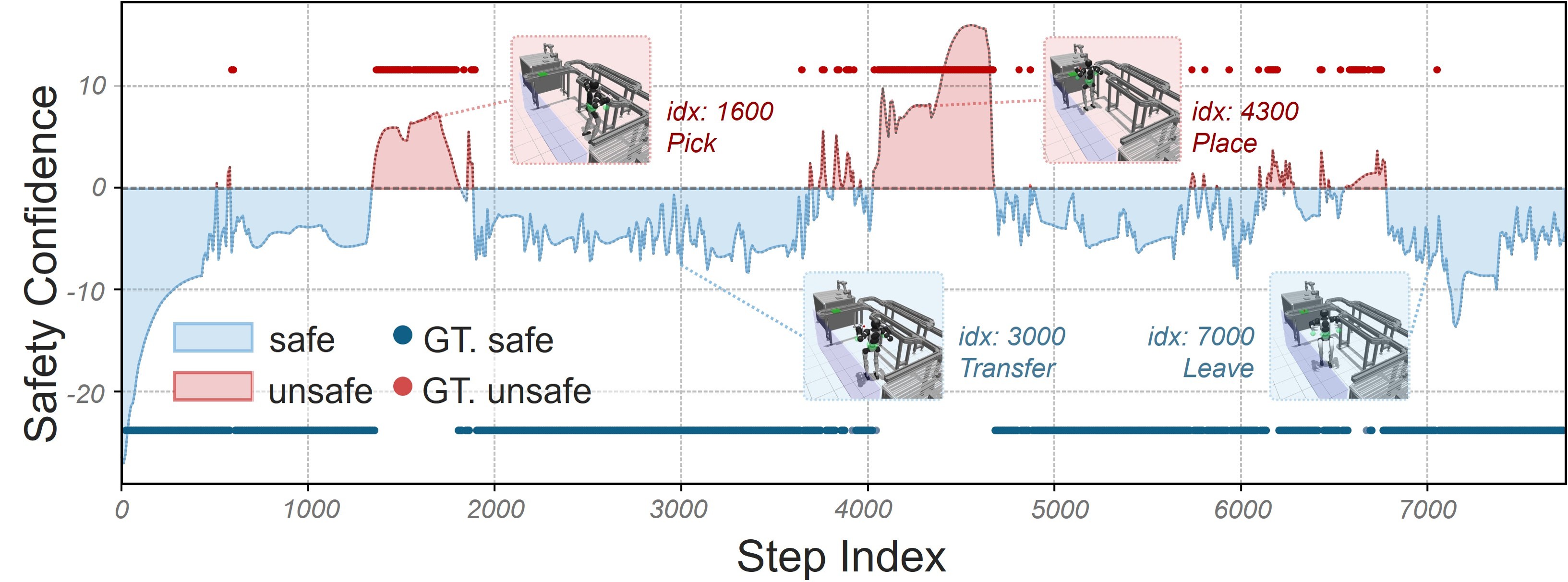
Each sampled state is evaluated by running the fallback controller forward until the robot either reaches the minimum-risk condition or violates safety constraints such as falls, forbidden collisions, or joint limits. Those outcomes become supervision for the monitor.
Unsafe stop failures are rare under nominal operation, which makes naive data collection inefficient. PRISM addresses this by iteratively retraining the monitor and then sampling more aggressively around the predicted safe versus unsafe boundary.
For sim-to-real transfer, nominal trigger states are taken from real robot logs and replayed in simulation before executing the fallback rollout. Domain randomization is then applied during fallback execution so the learned boundary remains useful on hardware.
The subset of nominal states from which the fallback controller can still reach the terminal safe set with high confidence.
A stable terminal posture used as the endpoint of the safe stop, chosen to minimize residual risk once the stop has been triggered.
The monitor can serve as a passive diagnostic after an external stop or as a proactive supervisor that triggers the fallback policy before irrecoverable states are reached.
The iterative training loop starts from a small nominal dataset.
PRISM grows the dataset gradually while reallocating where labels are collected.
Hardware nominal trajectories are replayed in simulation to reduce trigger-state mismatch.
Large-scale simulated rollouts provide the safe versus unsafe labels used for training.
Experiments / Results
Experiments evaluate the monitor on a 29-DoF humanoid performing a fixed loco-manipulation task. The paper emphasizes reducing false-safe predictions while keeping the total amount of hazardous data collection practical.
At the same data volume as the 30-trajectory uniform baseline, PRISM improves unsafe-state prediction from 78.3% to 87.9%.
PRISM reaches performance comparable to a 54-trajectory uniform baseline while using over 40% less collected data.
On held-out hardware trajectories, the importance-sampled monitor identifies unsafe states more reliably than the comparable uniform baseline.
Threshold tuning can push simulated unsafe-state accuracy above 99% when more conservative intervention is preferred.

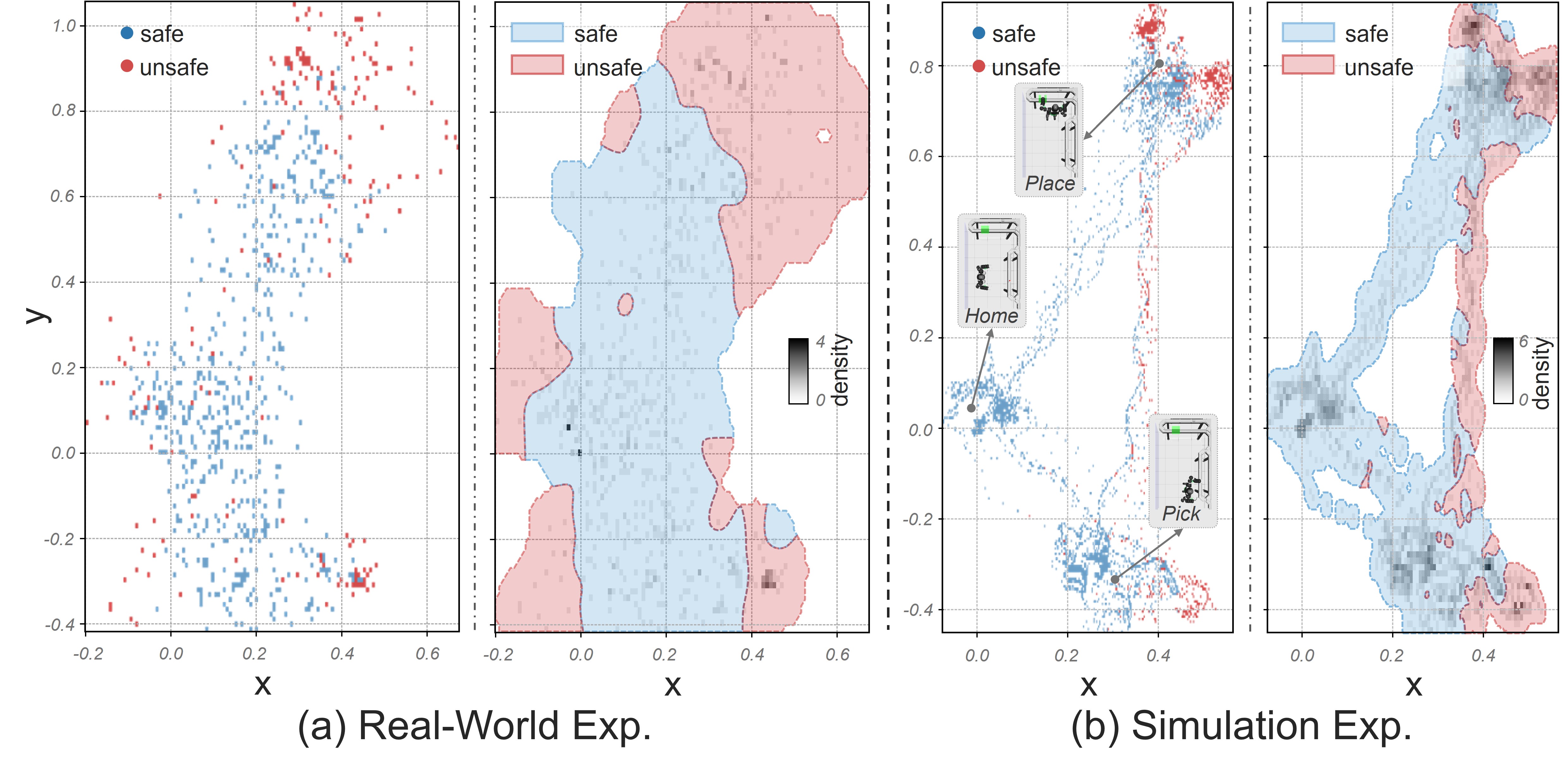
The paper reports strong zero-shot generalization under joint damping and gain randomization. Ground friction changes are more difficult because they alter the contact mechanics that define recoverability.
Denser temporal sampling improves accuracy but becomes expensive quickly. PRISM is useful because it spends that extra density only where the current monitor still makes costly mistakes.
Paper
The links on this page point to the latest manuscript PDF and demo video for this project.
The arXiv PDF contains the full safe-stoppability formulation, the PRISM refinement procedure, the sim-to-real analysis, and the experimental tables summarized on this page.